Swin Transformer1: Reading Notes
0. Abstract & 1. Introduction
- Aim to solve the large variations in the scale of visual entities and the high resolution of pixels in images
- Large variations in the scale of visual entities: one object has multiple visual scales. for instance, human can make up over 80% pixels or only takes few pixels.
- High resolution of pixels: this would be intractable for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic to image size. Or Add difficulty to semanticsegmentation that require dense prediction at the pixel level.
- Use the hierachical transformers with non-overlappig local shifted windows
This is the key feature of swin trasnformer. Windows here is like the kernel in CNN. but it is non-overlapping. In shifted window, all patches within it share the same key. On the other words, instead of based on patches, it is based on windows, which is a comabination of patches. So the pixels within this windows would use the same key as the query is from the same window.
But in the sliding windows, every patches would become a unqiue query as the sliding window attends to a limited range of elements in the input sequence.

- In the self-attention part, it achieves the linear complexity to the image size
9*h*w*c^2 + 2(h/m * w/m) * h*w *c, instead ofh*w*9*c^2 + 2 * (h*w)^2 * ch: weight w: width c: channels m: window size
It is a general backbone for image classification, object deteaction, semantic segmentation.
Tested on ImageNet-1k (for image classification), COCO (for object detection) and ADE20K (for semantic segmentaion), Its performance surpasses the previous state-of-theart.
- This work can help facilitate joint modeling of visual and textual signals and the modeling knowledge from both domains can be more deeply shared.
2. Related Work
CNN and variants
Various creation on CNN network: depth wise convolution, deformable convolution
Self-Attention based Backbone Architectures
Previously self-attentions use the sliding windows, makes it more latency than CNN.
Reasons is explained on 0. Abstract & 1. Introduction. So it uses the sliding windows.
Self-Attention/Transformers to Complement CNNs
Another way to complement CNNs is to augment a standard CNN architecture with self-attention layers or transformers.
Transformer based Vision Backbones
- ViT: Transformer for image classifications. And DeiT provides more training strategies for this.
Disadvantages: quadratic increase in complexity with image size
- Build multi-resolution feature maps on transformer. And its complexity is still quantratic to images size.
3. Method
3.1 Overall Architecture
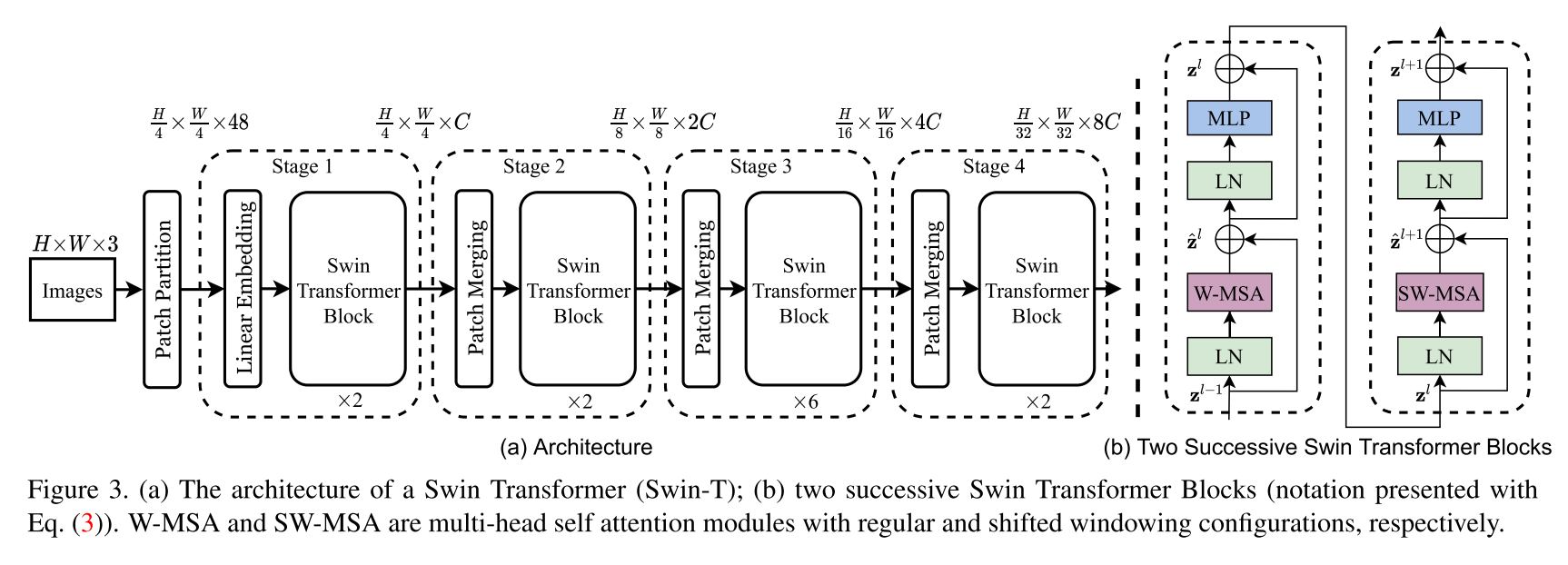
How to understand it ?
Here I have not looked into segmentation layers so leave it as “??”
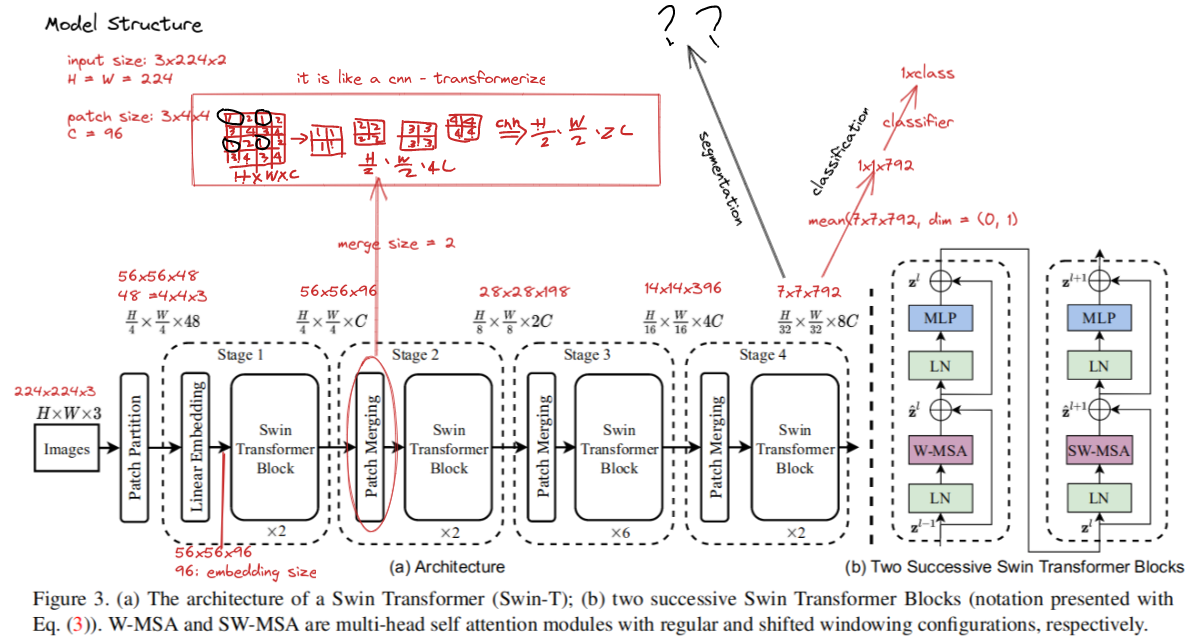
Swin tranformer block: A transformer block consists of a shifted window based MSA module, followed by a 2-layer MLP with GELU nonlinearity in between, as the above shows.
- Two swin transformer block, normal and shifted windows can be a complete one. So it explains why the number of swin transformer block is even
3.2. Shifted Window based Self-Attention
Self-attention in Non-overlapped Windows
- How is the computational complexity?

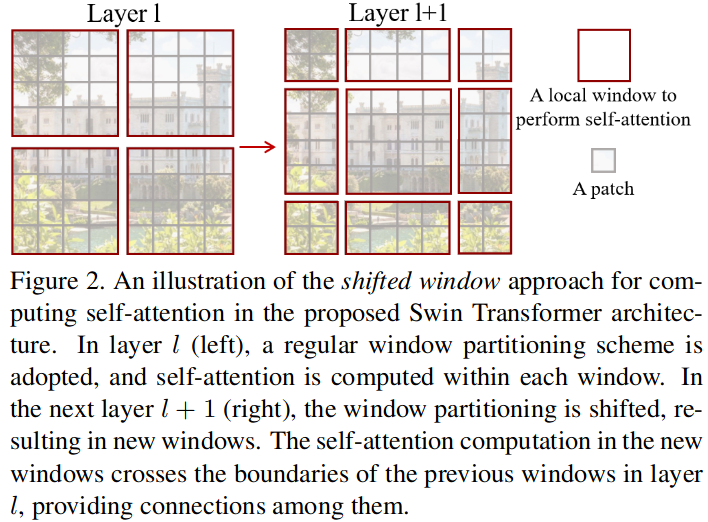
Shifted window partitioning in successive blocks
So How shifted windows work?
The first module uses a regular window partitioning strategy which starts from the top-left pixel, and the 8 × 8 feature map is evenly partitioned into 2 × 2 windows of size 4 × 4 (M = 4). Then, the next module adopts a windowing configuration that is shifted from that of the preceding layer, by displacing the windows by (M/2, M/2).
Cyclic-shift the patches towards the top-left direction and mask the moving part (A, B, C) since it is not close to the near in the feature maps
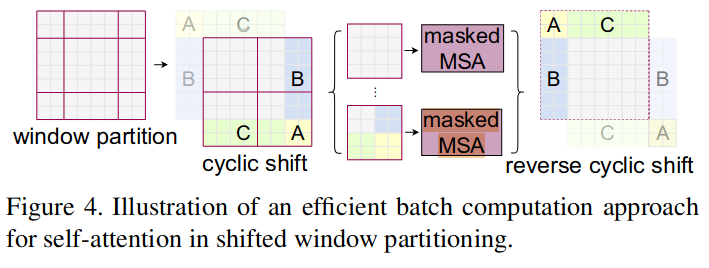
- So the computation is
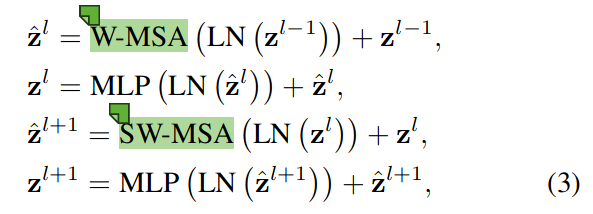
W-MSA: windows-multihead self-attention &nps;&nps;&nps;&nps; SW-MSA: shifted windows-multihead self-attention
- The shifted window re-partition the feature maps, so it creates connections within patches from the previous window
Relative position bias
- Add reative bias during the attention calculation
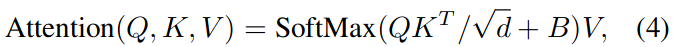
dis head/key/query dimensions - Since the relative position along each axis lies in the range [−M + 1, M − 1], we parameterize a smaller-sized bias matrix Bˆ ∈ R^(2M−1)×(2M−1), and values in B are taken from Bˆ
3.3. Architecture Variants
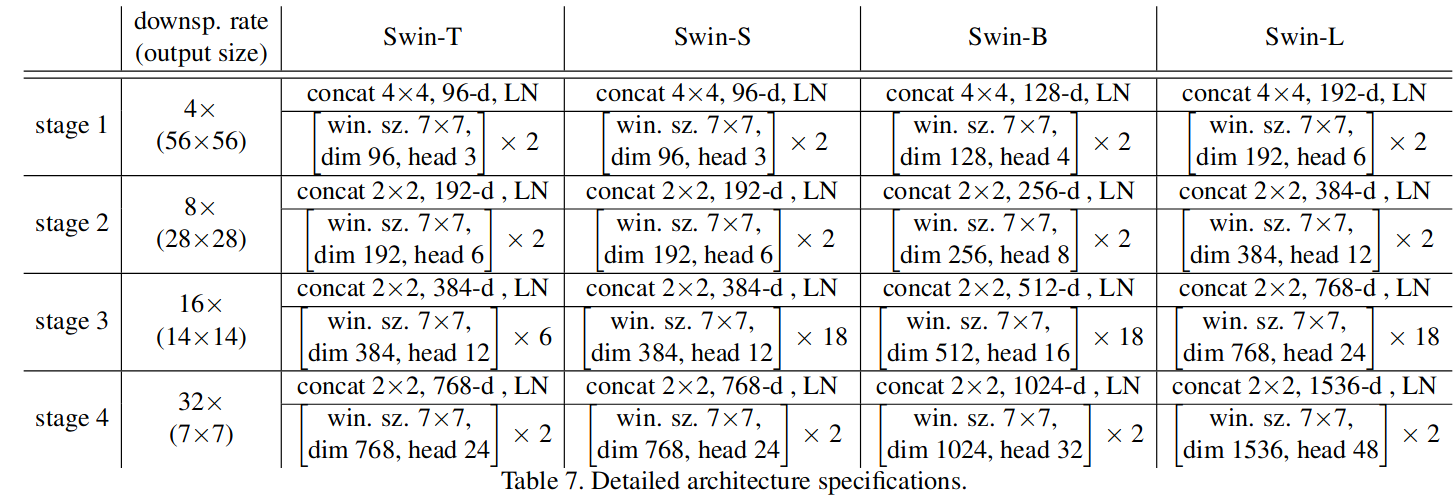
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
- Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
- Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
- Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
- C is the channel number of the hidden layers in the first stage
- layer numbers is a list of number of transformer blocks in every stage
4. Experiments
Not Be Covered
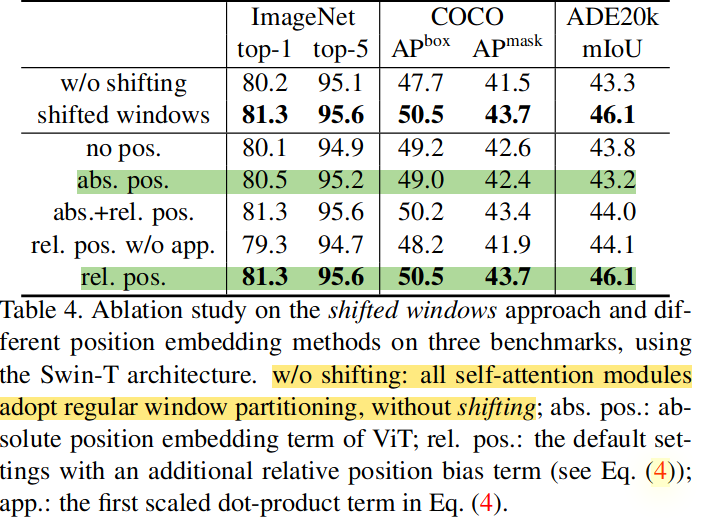
4.4 Ablation Study
Shifted Windows