SAM2: Model Structure
The Segment Anything Model(SAM) model structure has emerged as a fascinating and highly effective approach to large model in computer vision. Out of my expectation, for large models on computer vision, it starts with segmentation!
Here I am sharing the reading notes to demystify the SAM model structure, exploring its components from image encoder, prompt encoder and mask decoder. Let’s go!
SAM
- Link: https://ai.meta.com/research/publications/segment-anything/
- Github: https://github.com/facebookresearch/segment-anything
Model Structure
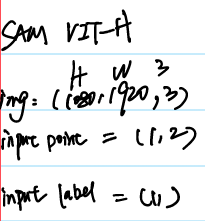
Input
Step1 Encoder Image
It provides the function predictor.set_image to encode images 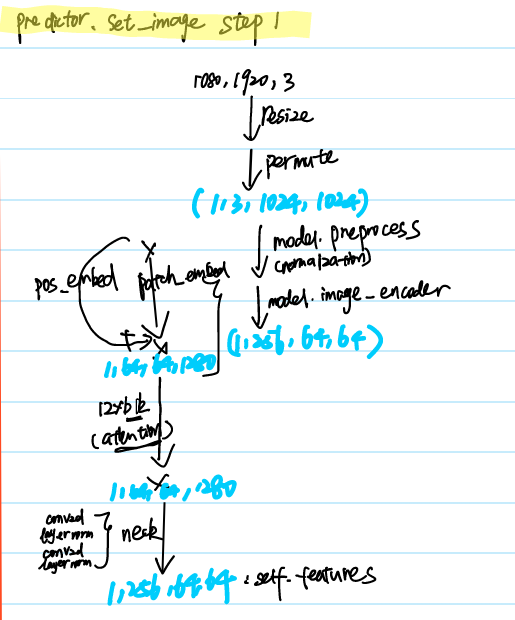
Step2 Predict
It sets the function predictor.predict to give the final ious and masks, with input from prompt, labels and encoded image features
Step2-1 Preprocess Prompt
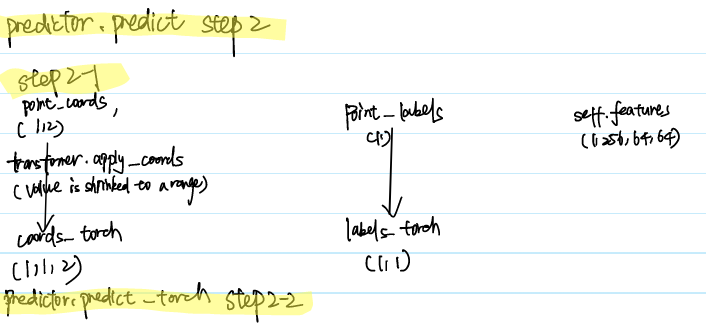
Step 2-2 Torchly Predict
After prompt preprocess, in predictor.predict_torch, inputs would be passed into the rest of model structure
Step2-2-1
It sets model.prompt_encoder to encode prompts
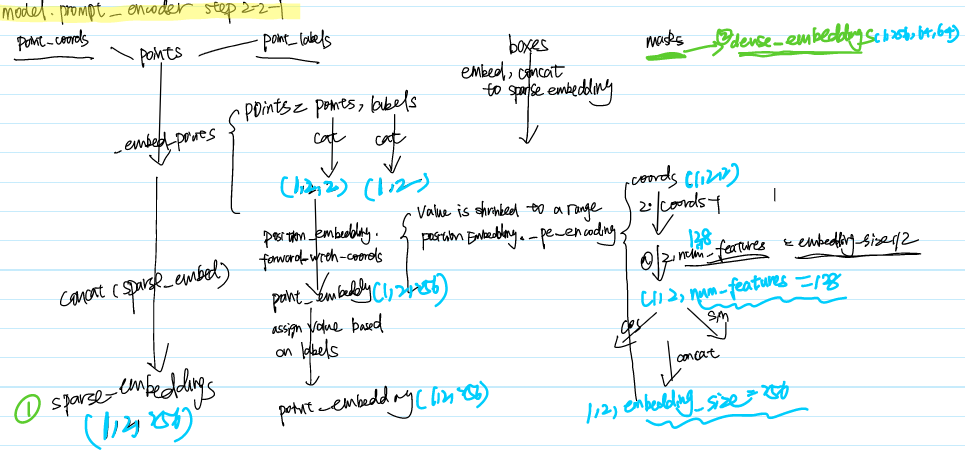
Step 2-2-2 Mask Decoder
model.mask_decoder is called to decode the result from encoded image and prompts 
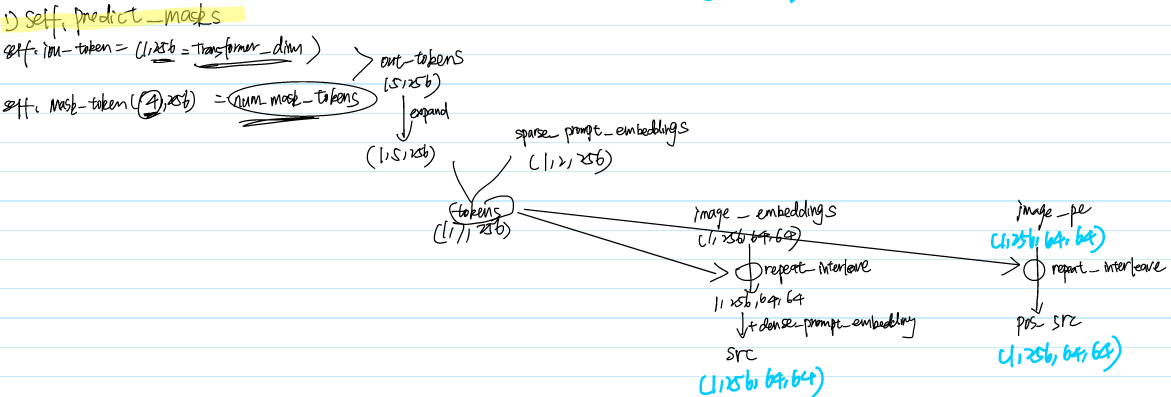
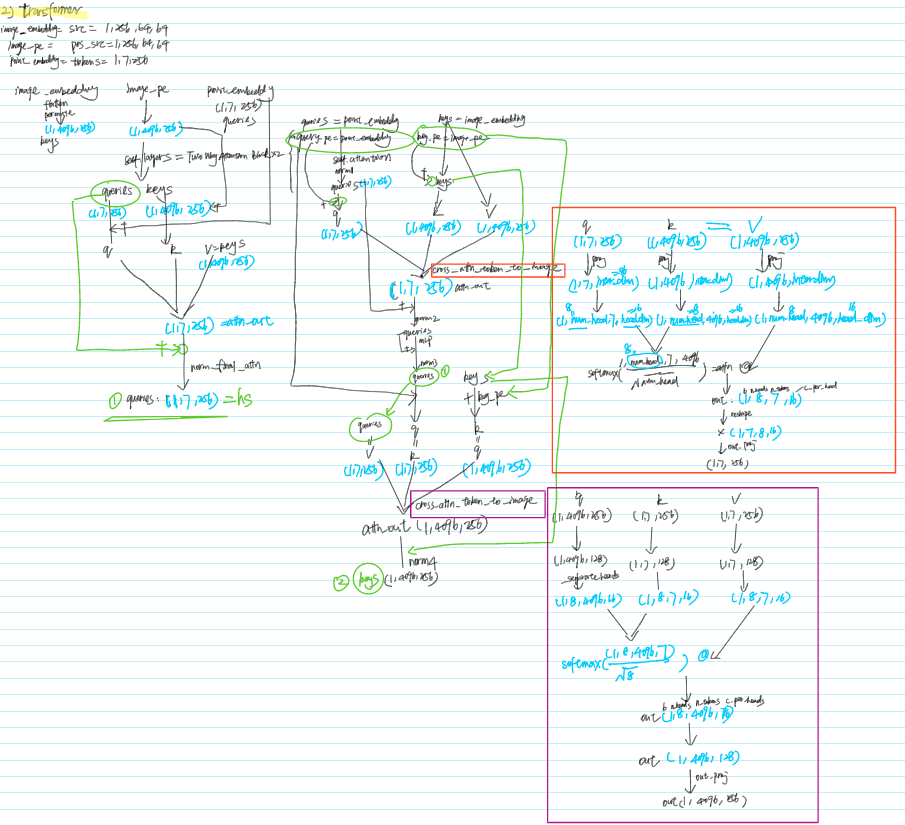
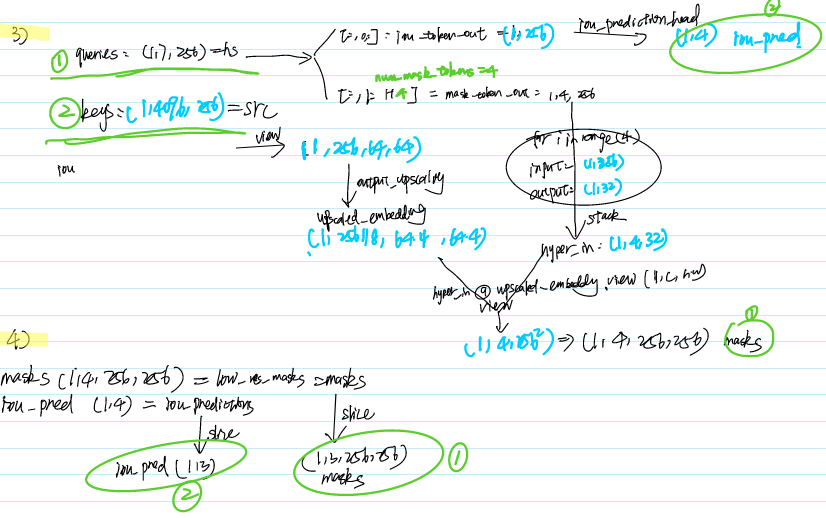
Step 2-2-3 Result Postprocess

That’s all. Thanks for reading it!
